02-3000字图文并茂的解析 webpack 核心库 enhanced-resolve 工作流程和插拔式插件机制
0. 食用本文的文档说明:
因为篇幅有限,希望你掌握以下前置条件:
- 希望你最好了解 订阅发布模型
- 希望你知道
tapable的 以下 3 个钩子函数AsyncSeriesBailHook, AsyncSeriesHook, SyncHook
通过本文你将学到如下内容(或者带着如下疑问去学习)
- 如何
调试一个 nodejs 开源库 - 了解
webpack解析库 enhance-resolve 的大致工作流程 - 初步了解 webpack/enhance-resolve 中
tapable的使用,以及插件机制实现的原理(这里写 webpack,是因为二者的插件机制是一样的实现原理)
本文 GitHub 解析地址: fu1996/enhanced-resolve at feature-study-enhanced (github.com)
先看全文,再考虑要不要给个star⭐️。
1. 初步了解该库的作用,明白这个库是干啥的?
想初步了解一个库的作用,以及建立初衷,最好的方式就是阅读当前库的README.md(前提是该库作者维护了此文档 😊)。
README.md内容如下:
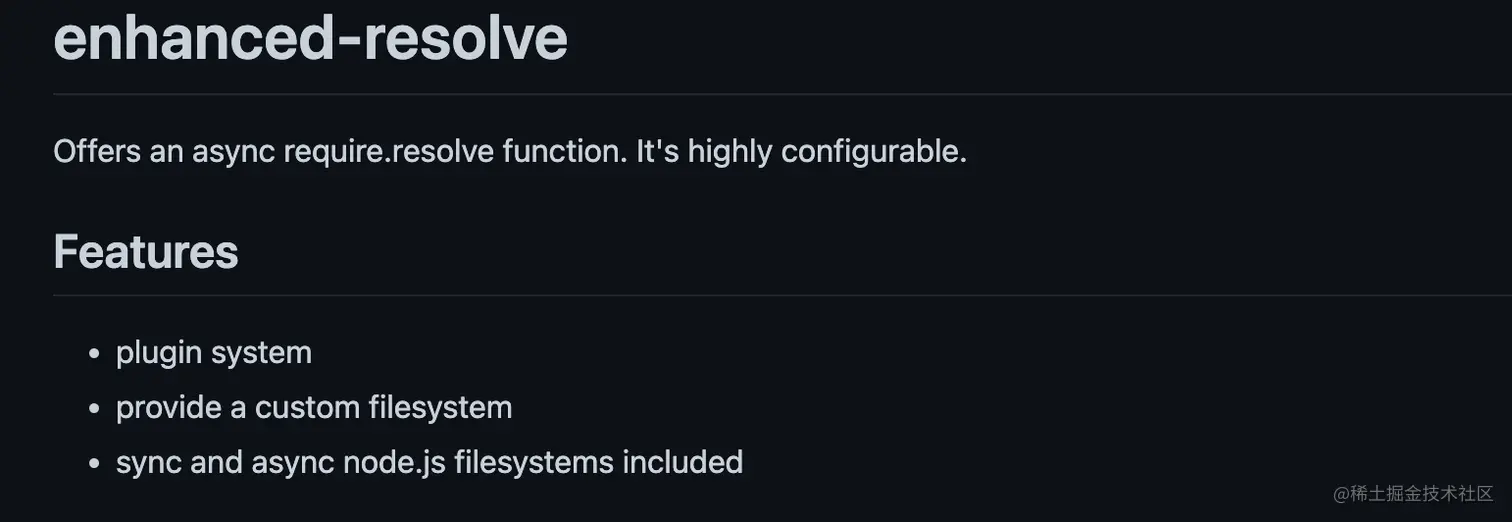 翻译为中文就是:
翻译为中文就是:
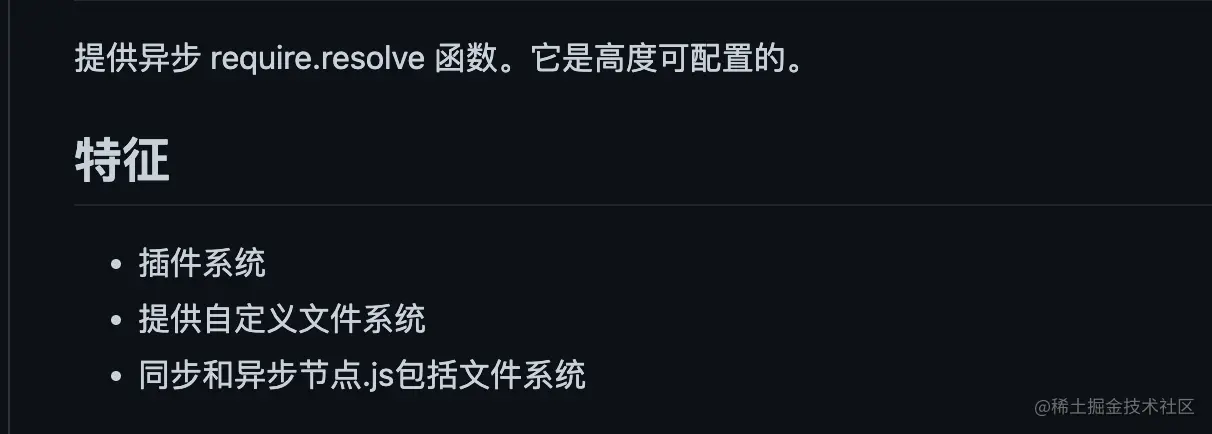 大家想了解关于原生的 require.resolve 的介绍可以看这篇文章 ===> node 的路径解析 require.resolve - 掘金 (juejin.cn)
大家想了解关于原生的 require.resolve 的介绍可以看这篇文章 ===> node 的路径解析 require.resolve - 掘金 (juejin.cn)
该库也是作为 webpack 里核心的依赖解析库存在,在 webpack.config.js 里配置的 resolve 字段 实际上就是当做参数传递给该库的,所以深入的了解一下该库的工作原理以及插件机制的实现,也有益于 webpack 的优化 和 后期阅读 webpack 源码。
2. 拉取并跑起来一个简单的 demo,初步了解该库对于 resolve 的 enhance (增强)
GitHub 地址如下:webpack/enhanced-resolve: Offers an async require.resolve function. It's highly configurable. (github.com) PS: 国外访问较慢,强烈推荐 使用 Gitee 导入该仓库 【不会吧,不会吧,都 2023 年了,竟然还有人不知道这个方法?📚】
代码拉取完毕以后,观察项目目录,发现使用的 yarn,执行 yarn install 进行安装依赖安装。如果没报错的话,写一个简单的 demo 小试牛刀。
新建一个 demo 文件夹,并创建 test-hook.js (名称可以自定义),然后写入如下内容:
const { ResolverFactory, CachedInputFileSystem } = require("../lib");
const fs = require("fs");
const path = require("path");
const myResolver = ResolverFactory.createResolver({
fileSystem: new CachedInputFileSystem(fs, 4000),
extensions: [".json", ".js", ".ts"],
});
const context = {};
const resolveContext = {};
const lookupStartPath = path.resolve(__dirname);
const request = "./a";
myResolver.resolve(
context,
lookupStartPath,
request,
resolveContext,
(err, path, result) => {
if (err) {
console.log("createResolve err: ", err);
} else {
console.log("createResolve path: ", path);
}
}
);
新建 a.js 文件(不必写入内容,该库只做路径解析), 此时文件目录如下:
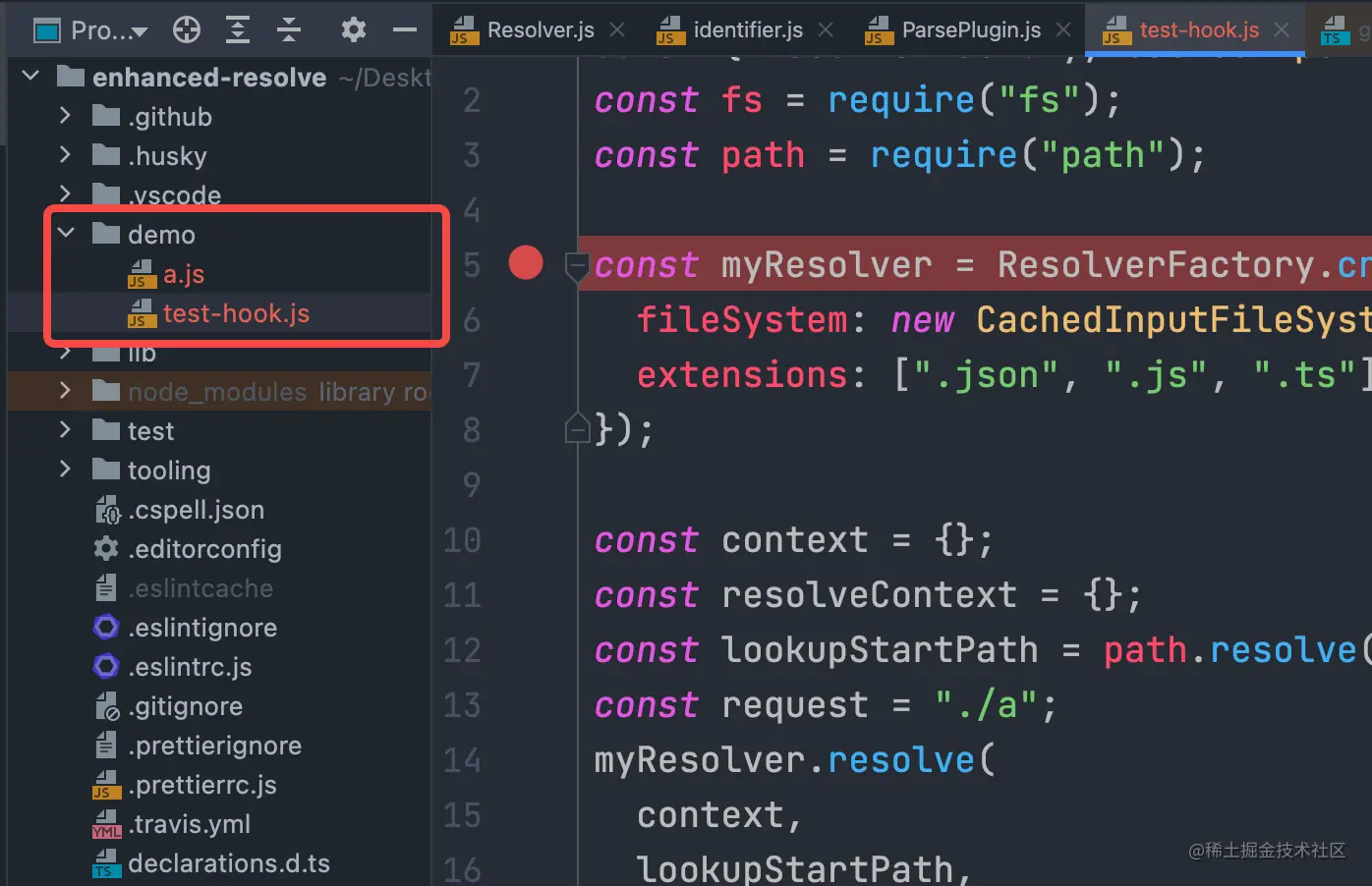
运行test-hook.js 输出如下:

demo 运行成功,第 2 关通过
3. 开启 Debug 模式,分析大体逻辑
本人喜欢用 webStorm 进行调试 (之前是搞 Python 开发的,习惯了)。
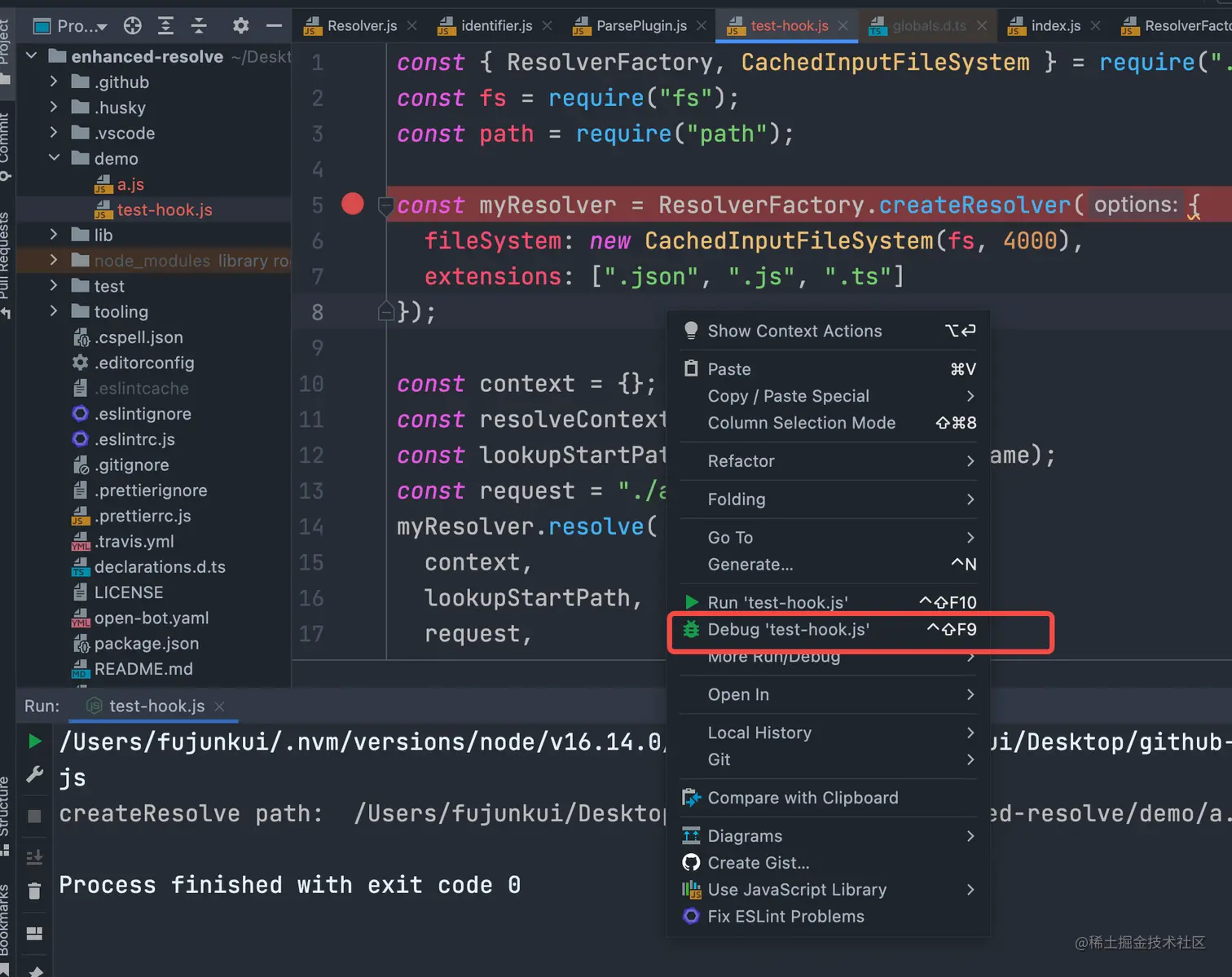
3.1 webStorm 使用 debug 模式 (不是本文重点,简单说明一下)
webStorm 的只需要 当前文件 下 右击,然后 点击 Debug test-hook.js 即可
 ’
’
3.2 vscode 使用 debug 模式
vscode 的 debug 方式很多,这里只说一个 自带 debug 终端 的调试方法,此法也是很方便调试 node 程序的。
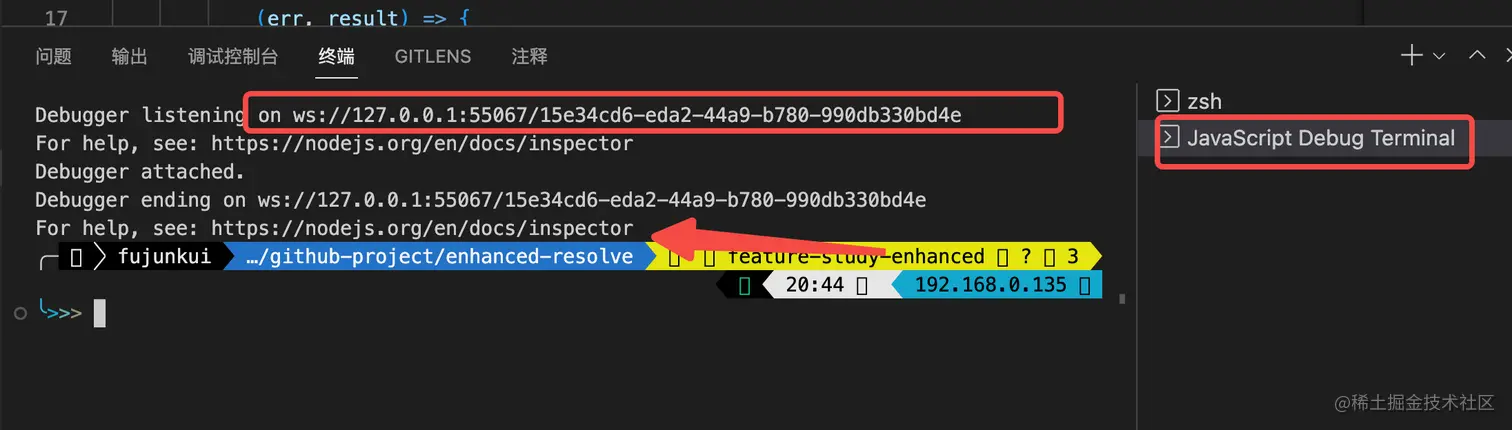
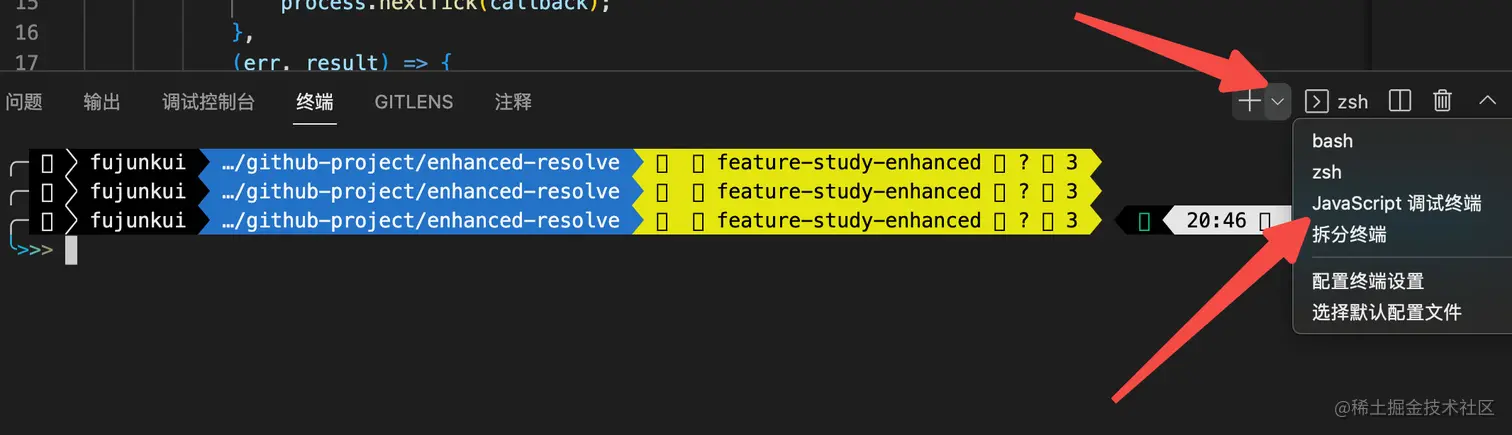 点击完毕以后,产生一个新的终端:(上面的 ws 地址 请自行探索)
点击完毕以后,产生一个新的终端:(上面的 ws 地址 请自行探索)
新的终端默认是在 根目录下的,随便在 test-hook.js 打一个 断点,然后 运行 node 命令:
node demo/test-hook.js
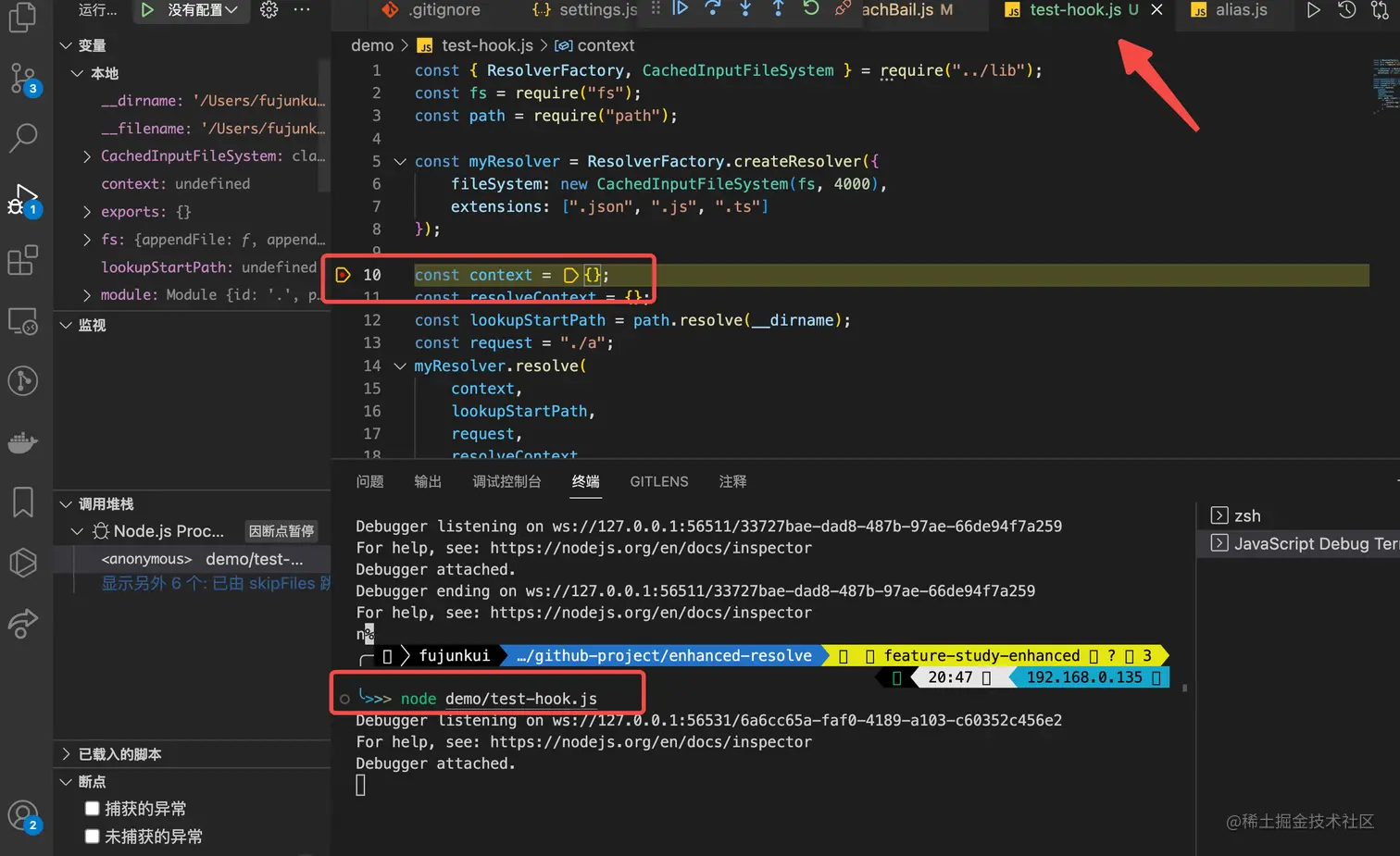
它就进来了。
3.2 分析大体逻辑
3.2.1 使用 ResolverFactory 工厂类 调用 createResolver 方法 创建一个 resolver 实例
const myResolver = ResolverFactory.createResolver({
fileSystem: new CachedInputFileSystem(fs, 4000),
extensions: [".json", ".js", ".ts"],
});
我看到这段的代码的主要逻辑就是去想:这方法吃了啥?吐出了啥?能根据变量名得到啥? 然后再去看方法的大致实现。
- 这方法吃了 类似于 webpack resolver 里的配置
- 从命名来猜测 这方法吐出了 一个 myResolver 的 对象
3.2.2 进入 createResolver 方法 大致分析流程 (进入该方法:按住 Ctrl + 【鼠标左键点击】)
这里只贴部分核心代码
exports.createResolver = function (options) {
// 解析并规范化用户传入的配置
const normalizedOptions = createOptions(options);
const {
plugins: userPlugins,
} = normalizedOptions;
// 深拷贝一下 用户用到的 plugins
const plugins = userPlugins.slice();
// 根据配置创建 resolver 实例
const resolver = customResolver
? customResolver
: new Resolver(fileSystem, normalizedOptions);
//// pipeline ////
// 确保该 hook 存在,不存在则注册它
resolver.ensureHook("resolve");
resolver.ensureHook("internalResolve");
// 根据配置 把用到的 内置 plugin 丢到 plugins 列表里
// resolve
for (const { source, resolveOptions } of [
{ source: "resolve", resolveOptions: { fullySpecified } },
{ source: "internal-resolve", resolveOptions: { fullySpecified: false } }
]) {
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
source,
cachePredicate,
unsafeCache,
cacheWithContext,
`new-${source}`
)
);
plugins.push(
new ParsePlugin(`new-${source}`, resolveOptions, "parsed-resolve")
);
} else {
plugins.push(new ParsePlugin(source, resolveOptions, "parsed-resolve"));
}
}
// ...省略部分plugins.push的逻辑代码...
//// RESOLVER ////
// 遍历 plugins 列表 并传入resolver 实例
for (const plugin of plugins) {
if (typeof plugin === "function") {
// 是函数 this 指向 resolver
plugin.call(resolver, resolver);
} else {
// 是类, 开始调用apply 方法 ,apply 方法 会注册一些 上面ensure的 hook
plugin.apply(resolver);
}
}
// 返回resolve 对象
return resolver;
};
一个简单的流程图如下:
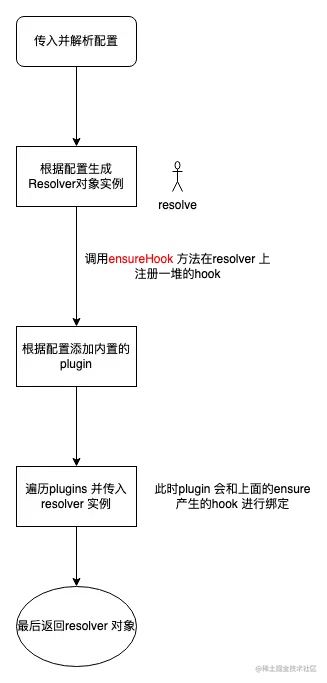
plugin.apply(resolver); 所有的事件 都已经成功订阅。
所有的钩子都在 resolver 对象 身上了 (子弹已经上膛,准备发射)。
3.3 粗略过下 Resolver 类的方法
我们使用 resolver 的 方式如下:
const context = {};
const resolveContext = {};
const lookupStartPath = path.resolve(__dirname);
const request = "./a";
myResolver.resolve(
context,
lookupStartPath,
request,
resolveContext,
(err, path, result) => {
if (err) {
console.log("createResolve err: ", err);
} else {
console.log("createResolve path: ", path);
}
}
);
那第一步就是 看 resolve 方法
3.3.1 初步了解 resolve 方法
核心代码如下:
看源代码时候不能心急,第一步 应该保大丢小,先掌握全局视角,然后逐个深入,看到后期,会有恍然大悟的感觉,原来那块写的是这个意思啊。🤔
class Resolver {
resolve(context, path, request, resolveContext, callback) {
// 所有流程的核心 就是这个 obj 对象
const obj = {
context: context,
path: path,
request: request,
};
const message = `resolve '${request}' in '${path}'`;
const finishResolved = (result) => {
return callback(
null,
result.path === false
? false
: `${result.path.replace(/#/g, "\0#")}${
result.query ? result.query.replace(/#/g, "\0#") : ""
}${result.fragment || ""}`,
result
);
};
const finishWithoutResolve = (log) => {
/`
* @type {Error & {details?: string}}
*/
const error = new Error("Can't " + message);
error.details = log.join("\n");
this.hooks.noResolve.call(obj, error);
return callback(error);
};
if (resolveContext.log) {
// We need log anyway to capture it in case of an error
const parentLog = resolveContext.log;
const log = [];
return this.doResolve(
this.hooks.resolve,
obj,
message,
{
log: (msg) => {
parentLog(msg);
log.push(msg);
},
yield: yield_,
fileDependencies: resolveContext.fileDependencies,
contextDependencies: resolveContext.contextDependencies,
missingDependencies: resolveContext.missingDependencies,
stack: resolveContext.stack,
},
(err, result) => {
if (err) return callback(err);
if (yieldCalled || (result && yield_)) return finishYield(result);
if (result) return finishResolved(result);
return finishWithoutResolve(log);
}
);
} else {
// Try to resolve assuming there is no error
// We don't log stuff in this case
return this.doResolve(
this.hooks.resolve,
obj,
message,
{
log: undefined,
yield: yield_,
fileDependencies: resolveContext.fileDependencies,
contextDependencies: resolveContext.contextDependencies,
missingDependencies: resolveContext.missingDependencies,
stack: resolveContext.stack,
},
(err, result) => {
if (err) return callback(err);
if (yieldCalled || (result && yield_)) return finishYield(result);
if (result) return finishResolved(result);
// log is missing for the error details
// so we redo the resolving for the log info
// this is more expensive to the success case
// is assumed by default
const log = [];
return this.doResolve(
this.hooks.resolve,
obj,
message,
{
log: (msg) => log.push(msg),
yield: yield_,
stack: resolveContext.stack,
},
(err, result) => {
if (err) return callback(err);
// In a case that there is a race condition and yield will be called
if (yieldCalled || (result && yield_)) return finishYield(result);
return finishWithoutResolve(log);
}
);
}
);
}
}
}
大致看完,发现这一步其实也是根据不同的条件去组装数据,把传入的数据,赋值到 obj 对象上,然后把 obj 对象传入doResolve 方法,当做此方法的第二个参数,真正调用的还是 doResolve 方法,下一步就是大致瞅下doResolve方法。
3.3.2 初步了解 doResolve 方法
上面resolve传递的 obj 对象作为 doResolve 的第二个参数,命名为:request,一起来看下。
doResolve(hook, request, message, resolveContext, callback) {
// 静态方法 根据当前 hook 信息 生成 调用栈信息
const stackEntry = Resolver.createStackEntry(hook, request);
let newStack;
// 当前 hook 调用栈信息 存入 newStack 里
if (resolveContext.stack) {
newStack = new Set(resolveContext.stack);
if (resolveContext.stack.has(stackEntry)) {
/`
* Prevent recursion
* @type {Error & {recursion?: boolean}}
*/
const recursionError = new Error(
"Recursion in resolving\nStack:\n " +
Array.from(newStack).join("\n ")
);
recursionError.recursion = true;
if (resolveContext.log)
resolveContext.log("abort resolving because of recursion");
return callback(recursionError);
}
newStack.add(stackEntry);
} else {
newStack = new Set([stackEntry]);
}
// 传入 hook, request 调用 resolveStep 的 hook
this.hooks.resolveStep.call(hook, request);
// 如果当前hook 被使用了
if (hook.isUsed()) {
const innerContext = createInnerContext(
{
log: resolveContext.log,
yield: resolveContext.yield,
fileDependencies: resolveContext.fileDependencies,
contextDependencies: resolveContext.contextDependencies,
missingDependencies: resolveContext.missingDependencies,
stack: newStack
},
message
);
// 触发当前hook 并传入 request 和 innerContext 当做参数
return hook.callAsync(request, innerContext, (err, result) => {
if (err) return callback(err);
if (result) return callback(null, result);
callback();
});
} else {
// 执行 callback 逻辑
callback();
}
}
callback的逻辑比较简单,我们应该看当前 hook (指的是:this.hooks.resolve)被使用的时候,resolve 的处理逻辑。
关键代码如下:
hook.callAsync(request, innerContext, (err, result) => {
当前 hook 直接调用了 callAsync 进行了 触发之前 plugin 的订阅事件,这时候我们要去找到之前 plugin.apply(resolver); 的时候,哪一个 plugin 的订阅类型 为resolve 事件。
3.3.3 去 ResolverFactory.js 文件寻找注册了 resolve 事件的 钩子
场景切回到 ResolverFactory.js 文件,显而易见的在 327 行左右 看到了这个注册事件,此 demo 的 unsafeCache 为false 所以此处 执行的是 347 行的代码 (关于此参数的作用,先 TODO 下,第一次看源码不能追深,应该追广)。这次要进入ParsePlugin 插件里,看它到底实现了哪些逻辑。(优秀的开源库,关于事件和数据的处理就是这么 callback,必须耐心 😊)
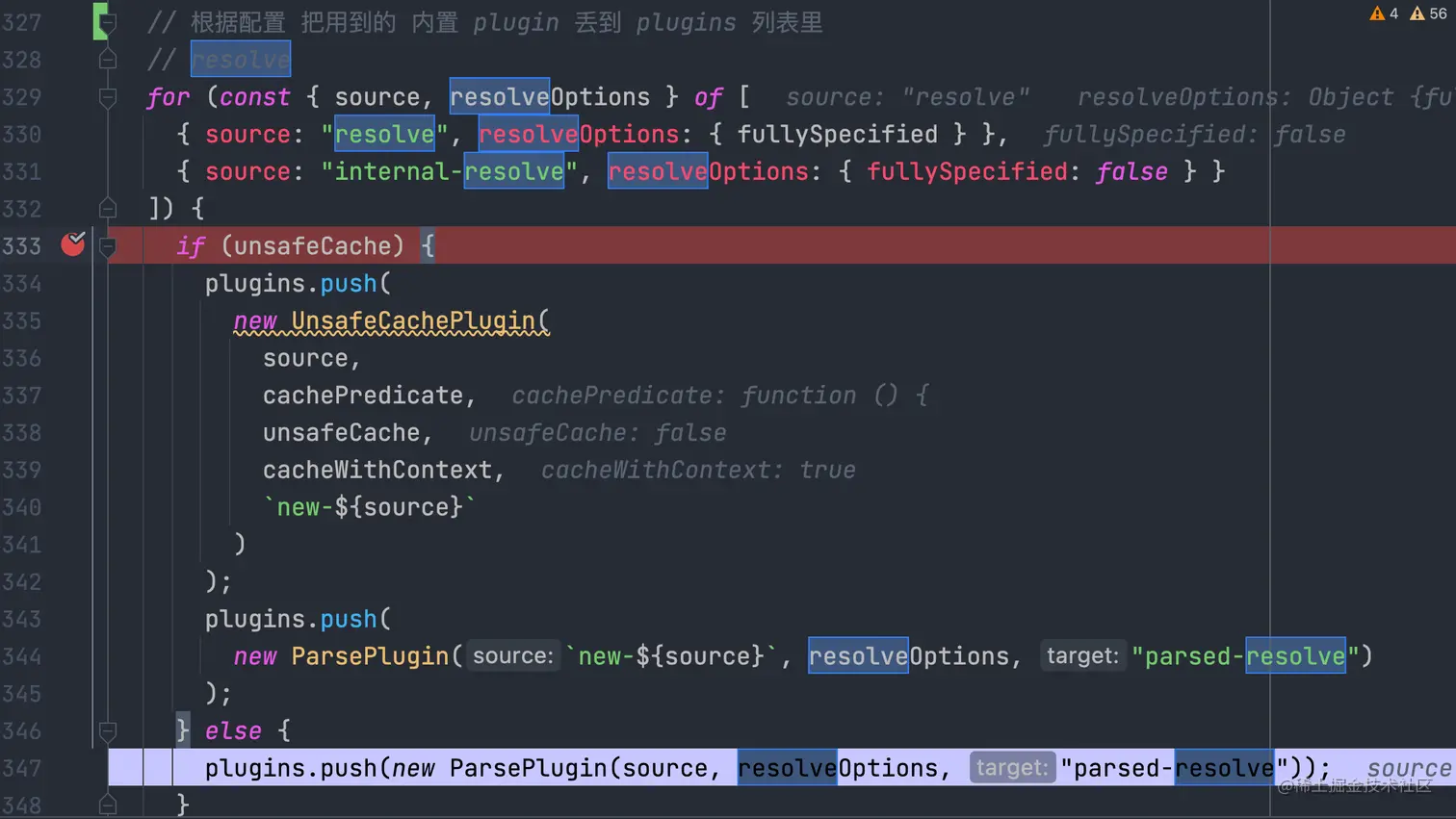
3.3.4 去 ParsePlugin 插件里,看最后一层的处理逻辑,实现闭环
ParsePlugin 插件,是当前主流程 闭环的结束,也是 文件解析 流程的开始,因为 从文章开头开始到现在,还没有真正的针对 文件解析 相关的事情 做相关操作,全是在注册一些 hook,实例化 Resolve 对象,处理格式化入参。
上代码,看具体逻辑,现身吧 我的小宝贝:
/*
MIT License http://www.opensource.org/licenses/mit-license.php
Author Tobias Koppers @sokra
*/
"use strict";
/` @typedef {import("./Resolver")} Resolver */
/` @typedef {import("./Resolver").ResolveRequest} ResolveRequest */
/` @typedef {import("./Resolver").ResolveStepHook} ResolveStepHook */
module.exports = class ParsePlugin {
/`
* @param {string | ResolveStepHook} source source
* @param {Partial<ResolveRequest>} requestOptions request options
* @param {string | ResolveStepHook} target target
*/
constructor(source, requestOptions, target) {
// 接受参数 并绑定到this 上
this.source = source;
this.requestOptions = requestOptions;
this.target = target;
}
/`
* @param {Resolver} resolver the resolver
* @returns {void}
*/
apply(resolver) {
// 这个resolver 就是之前 创建的 Resolver 的实体类
const target = resolver.ensureHook(this.target);
resolver
// 得到 this.source 对应的 hook
.getHook(this.source)
// 监听 this.source 对应的 hook,并设置 订阅函数
.tapAsync("ParsePlugin", (request, resolveContext, callback) => {
// 先初步解析 得到大致结果:
const parsed = resolver.parse(/` @type {string} */ (request.request));
// 合并参数
const obj = { ...request, ...parsed, ...this.requestOptions };
if (request.query && !parsed.query) {
obj.query = request.query;
}
if (request.fragment && !parsed.fragment) {
obj.fragment = request.fragment;
}
if (parsed && resolveContext.log) {
if (parsed.module) resolveContext.log("Parsed request is a module");
if (parsed.directory)
resolveContext.log("Parsed request is a directory");
}
// There is an edge-case where a request with ## can be a path or a fragment -> try both
if (obj.request && !obj.query && obj.fragment) {
const directory = obj.fragment.endsWith("/");
const alternative = {
...obj,
directory,
request:
obj.request +
(obj.directory ? "/" : "") +
(directory ? obj.fragment.slice(0, -1) : obj.fragment),
fragment: ""
};
// 这个 hook 做完了 它该做的事情了 进入 this.target 的 hook 逻辑吧,
// 并把当前hook 处理过的结果传递给this.target 的 hook
resolver.doResolve(
target,
alternative,
null,
resolveContext,
(err, result) => {
if (err) return callback(err);
if (result) return callback(null, result);
resolver.doResolve(target, obj, null, resolveContext, callback);
}
);
return;
}
resolver.doResolve(target, obj, null, resolveContext, callback);
});
}
};
你会发现这个插件 确实开始 进行 request 字段的解析了,终于 它开始分析你在 test-hook.js 传入的 "./a" 到底是文件夹,还是文件了。😄
const request = "./a";
在该插件又经过一系列的解析以后,发现又开始使用 resolver.doResolve 方法 流转到 this.target 的 hook 了。 场景回溯:
先回溯一下当前的 this.target 是代表的那个参数?
plugins.push(new ParsePlugin(source, resolveOptions, "parsed-resolve"));
然后回想一下resolver.doResolve 方法做了啥? 此时 hook 的入参是 "parsed-resolve", request 参数代表的是 resolve hook 处理过的 alternative 变量。
doResolve(hook, request, message, resolveContext, callback) {
// 静态方法 根据当前 hook 信息 生成 调用栈信息
const stackEntry = Resolver.createStackEntry(hook, request);
let newStack;
// 当前 hook 调用栈信息 存入 newStack 里
if (resolveContext.stack) {
newStack = new Set(resolveContext.stack);
if (resolveContext.stack.has(stackEntry)) {
/`
* Prevent recursion
* @type {Error & {recursion?: boolean}}
*/
const recursionError = new Error(
"Recursion in resolving\nStack:\n " +
Array.from(newStack).join("\n ")
);
recursionError.recursion = true;
if (resolveContext.log)
resolveContext.log("abort resolving because of recursion");
return callback(recursionError);
}
newStack.add(stackEntry);
} else {
newStack = new Set([stackEntry]);
}
// 传入 hook, request 调用 resolveStep 的 hook
this.hooks.resolveStep.call(hook, request);
// 如果当前hook 被使用了
if (hook.isUsed()) {
const innerContext = createInnerContext(
{
log: resolveContext.log,
yield: resolveContext.yield,
fileDependencies: resolveContext.fileDependencies,
contextDependencies: resolveContext.contextDependencies,
missingDependencies: resolveContext.missingDependencies,
stack: newStack
},
message
);
// 触发当前hook 并传入 request 和 innerContext 当做参数
return hook.callAsync(request, innerContext, (err, result) => {
if (err) return callback(err);
if (result) return callback(null, result);
callback();
});
} else {
// 执行 callback 逻辑
callback();
}
}
所以当前的this.target 指的是parsed-resolve 相关的 hook,相当的见名知意。至于接下来的流程,打算另开一篇文章去 解说 resolver 详细的 hook 流转过程,感兴趣的兄弟们可以自己拉代码进行学习。
4. 完结撒花
终于,经过了一路的兜兜转转,这个 resolve 终于开始解析了。来张流程图,总结一下全文。
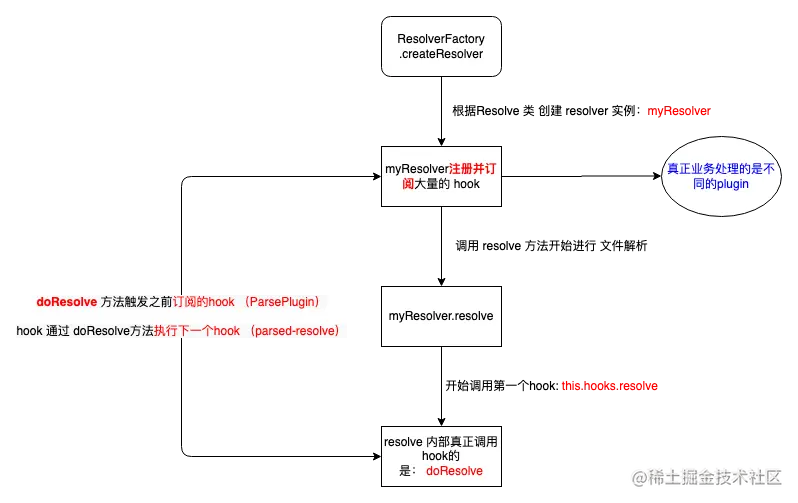
- ResolverFactory.createResolver 根据
Resolver类创建实例:myResolve(吃了配置,吐出对象myResolve) myResolve 上 注册并订阅大量的 hook (枪支弹药贮备好,一刻激发)- 调用
myResolver.resolve方法开始进行 文件解析 的主流程 - 内部通过
resolve.doResolve方法,开始调用第一个 hook:this.hooks.resolve - 找到之前 订阅 hook 的 plugin:
ParsePlugin ParsePlugin进行初步解析,然后 通过doResolve执行下一个 hookparsed-resolve,前期准备工作结束,链式调用开始,真正的解析文件的流程也开始。
本文 Gitee 解析地址:` [fujunkui/enhanced-resolve (gitee.com)](https://link.juejin.cn/?target=https%3A%2F%2Fgitee.com%2Ffujunkui1996%2Fenhanced-resolve) `【强烈推荐】
本文 GitHub 解析地址: fu1996/enhanced-resolve at feature-study-enhanced (github.com)
看到这里,如果感觉头痒(是要长知识了),学到了一丢丢知识,欢迎各位大佬点start。
下一篇文档:enhance-resolve 中的数据流动:【干货】耗时 7 个小时,用近 50 张图来学习 enhance-resolve 中的数据流动和插件调度机制 - 掘金 (juejin.cn)。