在AI大模型公司,是如何用AI代写CRUD业务代码?
1. 简单介绍
好久没有更新文章了,最近换了工作,已经从Develops行业转向AI大模型大模型行业。 最近打算做一个后台管理系统。公司前端目前只有我一个(从Python到React,又从React 到全栈),为了提高后台管理系统的便捷性,所以打算采用低代码平台去实现。 因为公司本身是搞AI大模型的,自然想要用上AI大模型的能力,去尝试提高我们的日常开发效率,说干就干。
省流版:
AutoCRUD-Tornado是一个基于 GPT、Tornado 和 PeeWee 的 AI 自动编写 CRUD 代码框架。 该框架可以帮助开发者快速生成数据库操作的代码,提高开发效率和减少重复工作。 无需手动编写 CRUD 操作代码,让 AI 来为您完成!欢迎加入我们,一起探索自动化编程的未来!
GitHub地址:https://github.com/fu1996/AutoCRUD-Tornado/tree/main
2. 三思而行
大模型对于结构化的数据比较亲和友好,所以后台管理系统中的前端界面需要采用结构化的数据,方便大模型进行理解。大模型后端语言的选择方面毫无疑问是Python啦,至于具体是哪个框架,有以下两个因素。
- 我司后端的业务代码都是采用 tornado 框架去搭建,为了普适性,还是继续选用 tornado 框架
- tornado框架诞生比较久了,所以大模型本身语料中也是有这部分数据的。
最后就是数据库模型层了,为了方便大模型理解和复写,这里采用 peewee ORM框架去描述模型结构,借助 peewee_async 去最大程度的发挥 tornado 框架异步的能力。
经过调研,发现amis使用json去描述前端界面的架构比较符合,这样的话,后台管理界面的结构化描述问题也解决了。
3. 框架搭建
简单的基于tornado搭建一个框架,我这里分为了如下几个模块,路由映射来接受路由,模型定义数据库结构,handler层 处理请求响应逻辑,control层处理 CRUD业务逻辑(单独抽出来,也方便进行单元测试),前端json文件描述界面。还有一些util,logger 之类的就不细说了。大致的目录结构如下:
├── conf # 配置文件目录
│ ├── local.env # 本地环境配置文件
│ └── prod.env # 生产环境配置文件
├── main.py # 项目启动入口
├── py_demo # 示例代码目录
│ ├── test_logging
│ ├── test_peewee
│ └── test_tornado
├── requirements.txt # 依赖包文件
├── server # 项目代码目录
│ ├── __init__.py
│ ├── config # 配置文件目录
│ ├── constant # 常量文件目录
│ ├── control # 控制层目录 【重要】
│ ├── db_manager # 数据库操作目录
│ ├── decorator # 装饰器目录
│ ├── handler # 处理层目录 【重要】
│ ├── logging # 日志目录
│ ├── model # 模型层目录【重要】
│ └── util # 工具类目录
├── static # 静态文件目录
│ ├── lark
│ ├── pages
│ └── public
└── template # 模板文件目录
├── index.html
└── lark.html
下面的流程图进行更加详细的数据流动说明。

4. 让 AI 开始代写
1. 给AI 进行角色定位
为了提高 AI 的准确度,防止出现幻觉,首先让 AI 有一个清晰的角色定位,也就是给AI添加预设词。比如:
## 角色定位
1. 你是一个专业的程序员,擅长使用 Python 语言进行 Web 开发。
2. 你是一个乐于助人的程序员,可以帮助用户解决编程问题。
3. 我将会问你一些问题,如果你回复代码,需要以markdown 的形式回复我。
## 技能特长:
1. 精通 Tornado 框架进行 Web 开发
2. 熟练使用百度的 AMIS 低代码平台
3. 能熟练运用 PeeWee ORM 库实现数据库操作
2. 提供现有的CRUD示例,开启 Few-shot
AI大模型是有一定的理解力,好的使用方式就是使用者尽可能清晰的去描述出相关的需求,这样才能提高准确度,并取得预期的效果,这里就要提到 Prompt工程。
代码是严肃的,因为一个字符的错误都会导致整个系统崩溃无法使用,所以大模型的准确度必须要高。在这里会使用 Few-shot 来提高准确度。
Few-shot 学习是通过提供少量的标注样本(即示例)来帮助模型理解任务。这些示例通常包括输入和预期输出,以便模型能够更准确地把握任务的性质和要求。对目标任务。由于该模型首先看到的是好的例子,它可以更好地理解人类的意图和需要什么类型的答案的标准。因此,Few-shot 学习往往比 zero-shot 学习有更好的性能。但是,这样做的代价是消耗更多的token,并且当输入和输出文本较长时,可能会达到上下文长度限制。详见:https://zhuanlan.zhihu.com/p/653956781
我们先简单的给大模型写点CRUD的案例,
我实现了一个amis 的低代码平台,接下来我将详细的介绍一下我的代码,你需要模仿我的代码去实现其他的能力。
下面是我的代码的逻辑,已经实现了一个CRUD 的逻辑。
## 路由定义
```python
# 授权用户的新增 和批量获取
(r"/api/auth_users", AuthUsersHandler),
# 授权用户的单条数据的增删改查
(r"/api/auth_user/(\d+)", AuthUserHandler),
```
## handler 处理的逻辑
```python
from server.control.user_auth_control import UserAuthControl
from server.handler.base_handler import BaseHandler
class AuthUsersHandler(BaseHandler):
async def get(self):
user_control = UserAuthControl()
page = self.get_argument("page", 1)
per_page = self.get_argument("perPage", 10)
params = self.get_all_argument
print(params)
data = await user_control.get_page_table(page=int(page), per_page=int(per_page), id=params.get("id"),
name=params.get("name"), phone=params.get("phone"))
self.success(data)
async def post(self):
print("新增接口", self.json_data)
user_auth_control = UserAuthControl()
public_key = "axxxx"
private_key = "qwer"
final_data = {
**self.json_data,
"public_key": public_key,
"private_key": private_key
}
res = await user_auth_control.create_one(**final_data)
self.success(res.id)
async def delete(self):
# ids 是一个 以逗号分隔的字符串
ids = self.get_query_argument("id")
id_list = ids.split(",")
print(f"delete: {ids}, id_list: {id_list}")
user_control = UserAuthControl()
res = await user_control.delete_by_ids(id_list)
self.success("ok")
class AuthUserHandler(BaseHandler):
async def put(self, id):
user_control = UserAuthControl()
res = await user_control.update_one_by_id(id, **self.json_data)
print("id", id)
self.success("ok")
async def delete(self, id):
user_control = UserAuthControl()
res = await user_control.delete_one_by_id(id)
print("id", id)
self.success("ok")
```
## control 处理的逻辑
```python
import asyncio
from typing import Dict, Optional
from playhouse.shortcuts import model_to_dict
from server.control.base_control import BaseControl
from server.db_manager import db_manager
from server.model.user_auth import UserAuth, UserAuthPydantic
class UserAuthControl(BaseControl):
async def create_one(self, **kwargs) -> UserAuthPydantic:
data = await db_manager.create(UserAuth, **kwargs)
return UserAuthPydantic(**model_to_dict(data))
async def get_one_by_id(self, user_id) -> Optional[Dict[str, str]]:
res = await db_manager.get_or_none(UserAuth.select().where(UserAuth.id == user_id))
if not res:
return None
serializer_data = BaseControl.serializer(res)
return serializer_data
async def update_one_by_id(self, user_id, **kwargs) -> Optional[Dict[str, str]]:
query = UserAuth.update(**kwargs).where(UserAuth.id == user_id)
return await db_manager.execute(query)
async def delete_one_by_id(self, user_id) -> Optional[Dict[str, str]]:
query = UserAuth.soft_delete().where(UserAuth.id == user_id)
return await db_manager.execute(query)
async def delete_by_ids(self, ids=None):
if ids is None:
ids = []
# 多个 ids
query = UserAuth.soft_delete().where(UserAuth.id.in_(ids))
return await db_manager.execute(query)
async def get_page_table(self, page, per_page, id, name, phone):
search_query = UserAuth.is_deleted == 0
if id:
search_query &= (UserAuth.id == id)
if not id:
if name:
search_query &= (UserAuth.name.contains(name))
if phone:
search_query &= (UserAuth.phone.contains(phone))
res = await asyncio.gather(
db_manager.execute(
UserAuth.select().where(search_query).paginate(page=page, paginate_by=per_page)),
db_manager.count(UserAuth.select().where(search_query)),
)
serializer_list = BaseControl.serializer_list(res[0])
list_data = {
"rows": serializer_list,
"count": res[1]
}
return list_data
```
## model 层的定义
```python
from datetime import datetime
from peewee import *
from server.model.base_model import BaseDBModel, BasePydanticModel, Field as PyField
class UserAuthPydantic(BasePydanticModel):
name: str
phone: str
mac: str
expire_time: datetime
create_time: datetime = PyField(default_factory=datetime.now)
public_key: str
private_key: str
remark: str = None
class UserAuth(BaseDBModel):
name = CharField(max_length=100, verbose_name="客户名称")
phone = CharField(max_length=100, verbose_name="电话")
mac = CharField(max_length=100, verbose_name="MAC地址")
expire_time = DateTimeField(formats="%Y-%m-%d %H:%M:%S", verbose_name="到期时间")
auth_time = DateTimeField(default=datetime.now, formats="%Y-%m-%d %H:%M:%S", verbose_name="授权时间")
public_key = TextField(verbose_name="公钥")
private_key = TextField(verbose_name="私钥")
remark = TextField(default="", verbose_name="备注")
class Meta:
db_table = 'user_auth'
verbose_name = '用户授权'
```
## 列表的json定义
```json
{
"title": "客户授权管理",
"remark": "客户列表",
"name": "user_auth_CRUD",
"headerToolbar": [
{
"type": "button",
"actionType": "dialog",
"label": "新增",
"icon": "fa fa-plus pull-left",
"primary": true,
# 以下省略很多行,很多行,很多行,很多行
}
]
}
```
3. 有了示例以后,开始提需求
我们把自己写的一个CRUD 实例提供给大模型以后,它在一定程度上是可以理解路由,模型定义,handler层 ,control层和前端界面间的联系的。接下来我们只需要提出我们的需求,让它进行代写即可。
## 上面的就是我写的全部的代码内容,接下来,我将会把新的模型定义提供给你,你需要写出j基于此模型定义的如下内容
1. 新模型的路由定义
2. 新模型的handler 处理的逻辑
3. 新模型的 control 处理的逻辑
4. 新模型的列表的json定义
5. 新模型的新增单个项的json定义
## 新的模型定义
```python
from peewee import *
from server.model.base_model import BaseDBModel, BasePydanticModel
class TodoItemPydantic(BasePydanticModel):
title: str
description: str
completed: bool
user_id: int
class TodoItem(BaseDBModel):
title = CharField(max_length=255, null=False, verbose_name='标题')
description = TextField(null=True, verbose_name='描述')
completed = BooleanField(default=False, verbose_name='是否完成')
user_id = IntegerField(null=False, verbose_name='用户ID')
class Meta:
db_table = 'todo_item'
verbose_name = 'TODO事项表'
4. 需求提完以后,开始代写。
大模型的角色定义,示例,和用户需求都准备完毕了,就可以让大模型进行代写了。我这里用了langchain的框架,简单实现一下:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import OpenAI, ChatOpenAI
OpenAILLM = ChatOpenAI(
openai_api_key="your-key",
openai_api_base="your-proxy",
temperature=0,
)
def chat_with_model(model, text):
resp = model.invoke(text)
content = resp if isinstance(resp, str) else resp.content
return content
def generate_prompt():
return ChatPromptTemplate.from_messages(
[
("system", """
## 角色定位
1. 你是一个专业的程序员,擅长使用 Python 语言进行 Web 开发。
2. 你是一个乐于助人的程序员,可以帮助用户解决编程问题。
3. 我将会问你一些问题,如果你回复代码,需要以markdown 的形式回复我。
## 技能特长:
1. 精通 Tornado 框架进行 Web 开发
2. 熟练使用百度的 AMIS 低代码平台
3.能熟练运用 PeeWee ORM 库实现数据库操作
"""),
("human", "{human_question}"),
]
)
def generate_openai_prompt(input_question):
prompt = generate_prompt().invoke({
"human_question": input_question
})
return prompt
question="内容太长了,这里不粘贴了,详见:https://github.com/fu1996/AutoCRUD-Tornado/blob/main/ai_crud/ai_crud_code.py"
content = chat_with_model(OpenAILLM, generate_openai_prompt(question))
with open("output_todo.md", "w", encoding="utf-8") as f:
f.write(content)
print(content)
因为大模型输出的业务代码太多了,简单的将其存为markdown 文件。大致粘一下具体的输出。
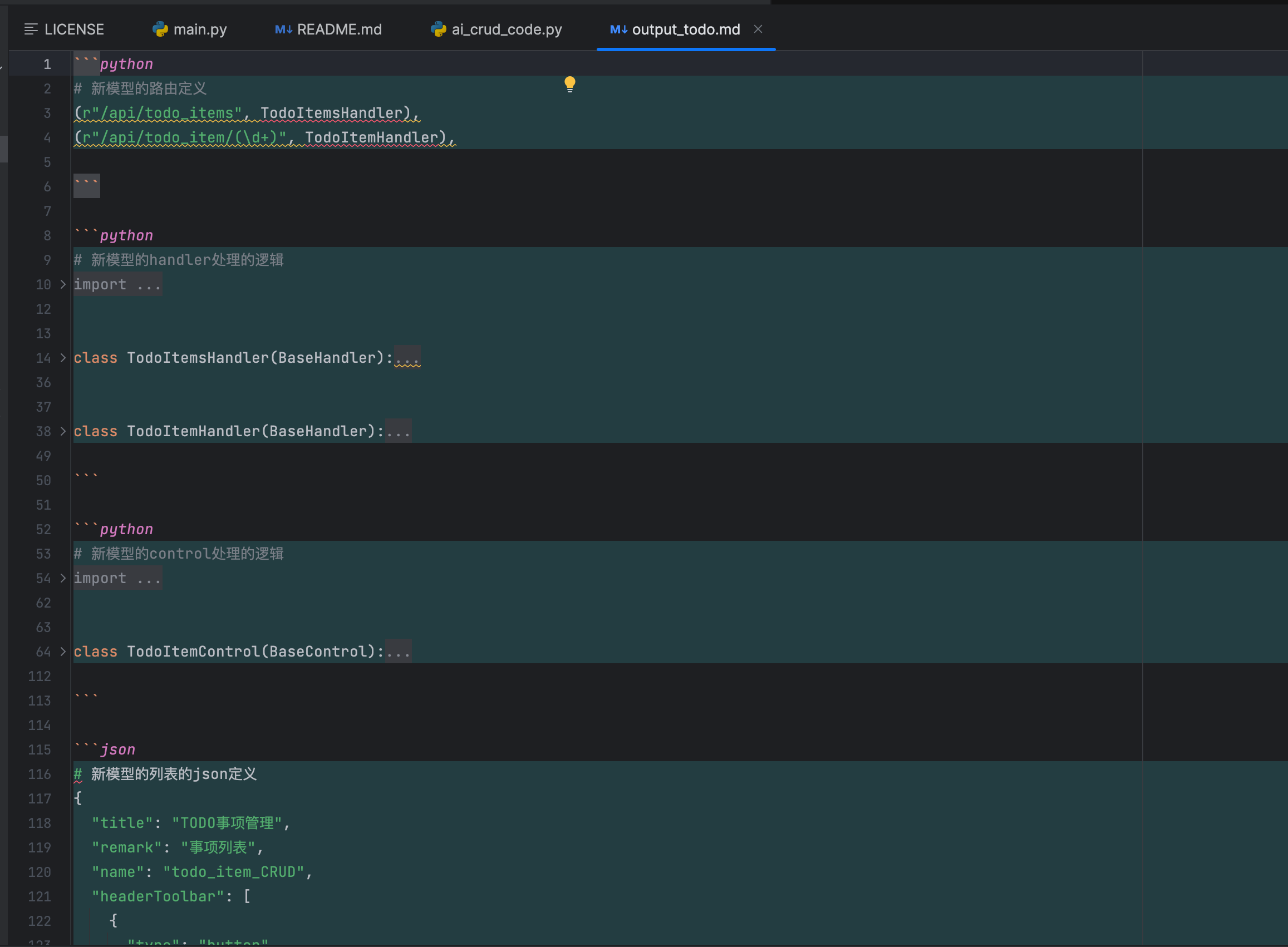
然后我们在将对应的输出手动粘贴到代码里【这里可实现自动化的能力~】。
启动一下,然后看下界面,这里发现 大模型生成的amis 的 json 文件有一处不对,需要人工校正一下。
# 大模型生成的
{
"type": "input-checkbox",
"name": "completed",
"label": "是否完成",
"required": true
},
# 查询完amis API 后校正的
{
"type": "checkbox",
"name": "completed",
"label": "是否完成",
"required": true
},
总的来说,效果还是很满意的,效率杠杠的。👍🏻👍🏻👍🏻
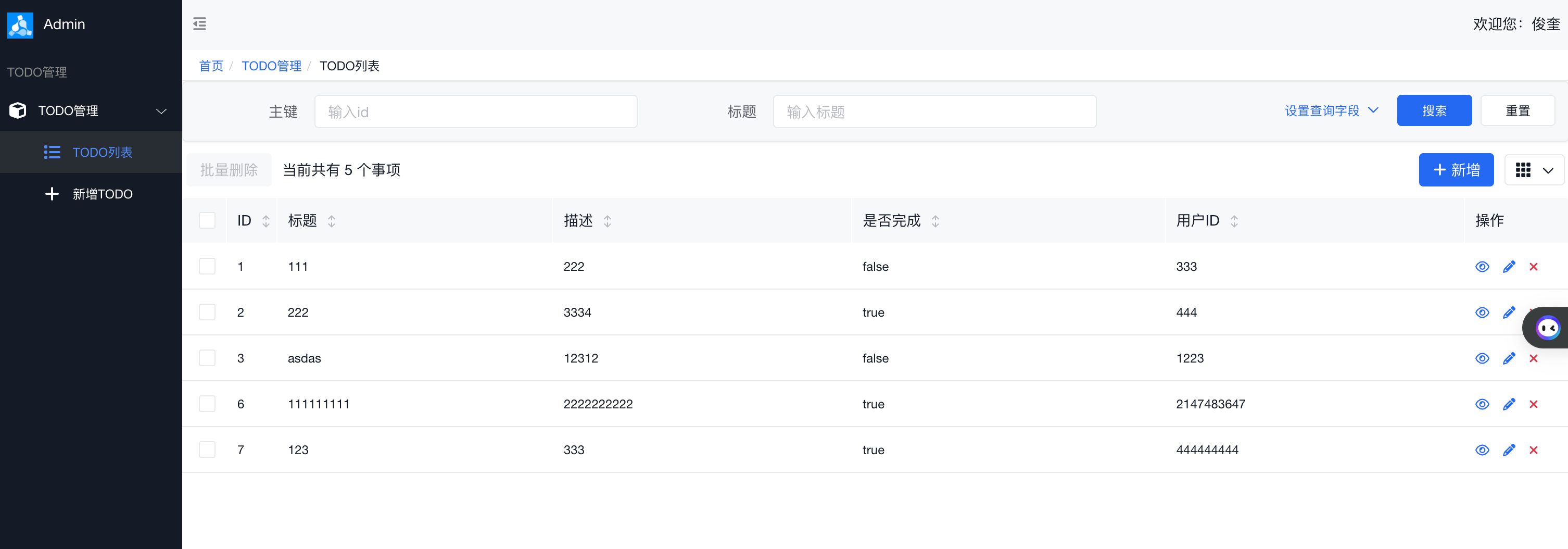
校正后的界面如下:
列表页:
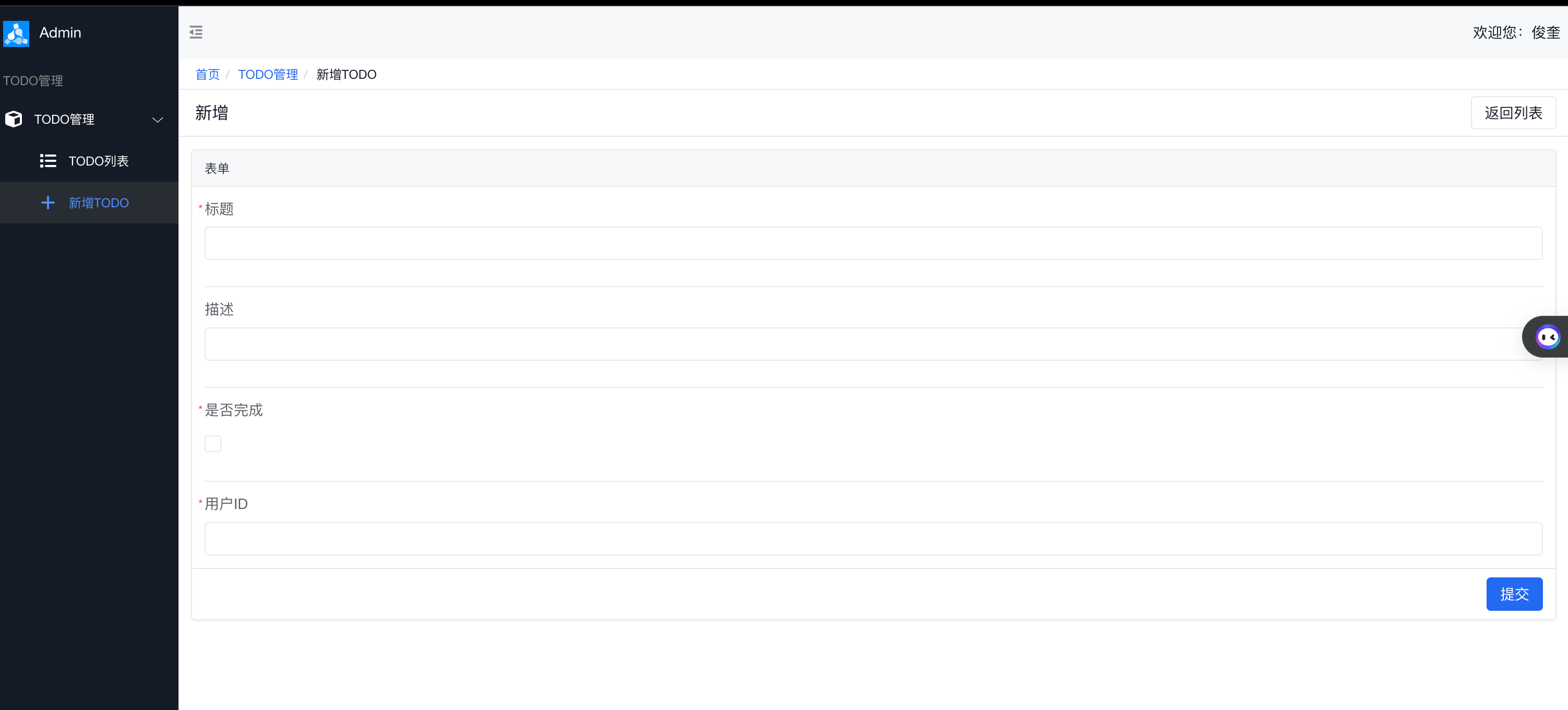
新增页:
搜索能力:
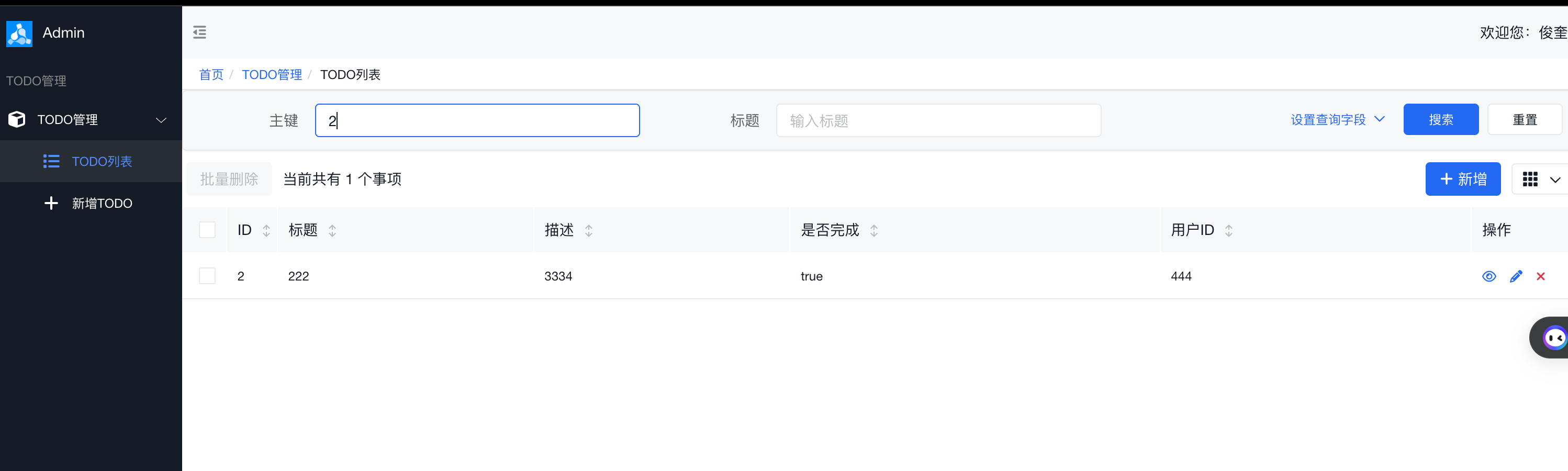
5. 总结
以上所有的代码都放到GitHub代码库了:https://github.com/fu1996/AutoCRUD-Tornado/tree/main,如果看完感觉还不错,有所收获,欢迎点个star ⭐️,后续再学习的更深入一些后,尽可能的去实现 让大模型当打工人,无需人为介入,实现自然语言编程。
因为篇幅和主题的原因主要讲的是AI 方面的内容,就没有讲太多使用Python进行框架搭建的内容,在进行Python tornado的框架搭建中,也有不少的感悟,简单的汇总收集一下,希望能帮到大家和自我继续成长。
- 要先大致的通读一下 tornado 框架文档,不要求熟记每一个部分(天才除外),目的是为了在搭建项目得过程中可以想到有哪些官方的方法可以结合,提高开发的幸福感和尽可能的发挥框架的威力 (大模型也会遗忘,建立知识的索引比记住知识的全貌对我的大脑来说更加高效)。
- 尽可能的去使用异步操作去发挥tornado 异步的威力
- 要在搭建的前期,尽可能的使用面向对象的思维和特性(因为前段时间一直在做前端,首先想到的还是函数式编程实现),去提高代码质量,耦合性和可读性,底层基础架构搭建的好,上层业务逻辑写的应该还可控。
- 在python中要注意对象的实例化模式,比如模型的链接池对象,使用单例模式会减少资源的消耗。(来自领导Code Review的收获)
- 框架的基础架构搭建完毕以后,尽可能的去完善 readme.md文件,因为大家的时间都很宝贵,所以 一份好的项目介绍文档是很重要,很提效的,这也是方便自己后期查阅(子曰:好记性不如烂笔头)。